RCNN은 2014년 SOTA를 주름잡는 Detection 모델이었고, 딥러닝 알고리즘(ConvNet)을 적용했다는 점에서 상당한 주목을 받았다.
하지만 Selective Search를 통해 2000개의 Region Proposals을 찾은 후 각각의 Region으로부터 CNN을 수행했기 때문에 엄청난 연산비용이 필수불가결했다.
RCNN이 나온지 1년 후 Fast R-CNN이 발표되었다. Fast R-CNN은 Selective Search와 CNN의 순서를 바꿈으로써 연산량을 획기적으로 줄였다는것이 핵심이다.
Concept
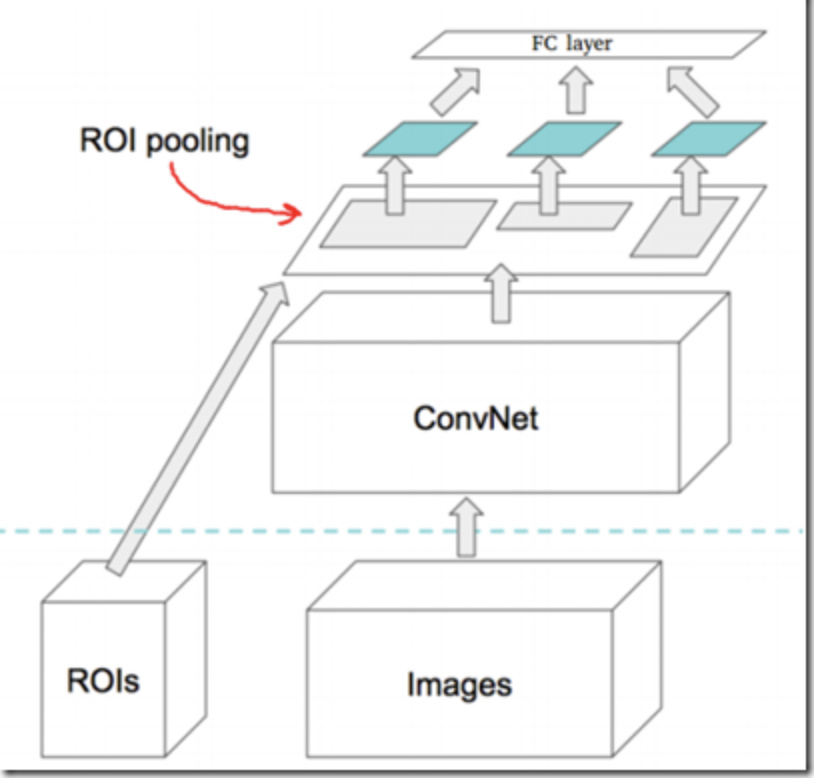
Fast R-CNN은 다음의 순서로 진행이 된다.
- Selective Search를 시행하여 Region Proposal의 Bounding Box 좌표값을 획득.
- 이미지를 CNN(VGG16)에 통과시켜 Feature Map을 추출.
- Bounding Box의 좌표값을 통해 FeatureMap을 Crop한 후, ROI Pooling을 수행.
- Pooling의 결과로 얻는 Feature는 FC Layer를 통과하여 Classification과 Bounding Box Regression을 진행.

1. Selective Search
Fast RCNN의 가장 큰 특징중 하나는 SS와 CNN의 순서가 바뀌었다는점이다. 그런데 "왜 첫번째 순서로 Selective Search가 나오는가?" 에 대한 이유는 다음과 같다. CNN을 통해 나온 Feature Map을 통해서는 SS를 적용하기 곤란하기 때문이다. Feature Map은 추상화된 이미지의 형태이기 때문에 색, 질감, 명암 등의 정보를 활용할 수 없다. 그래서 첫번째 시행에서 SS를 통해 RP을 추출하고 Bounding Box 좌표값을 얻는 과정이 필요한것이다.
2. CNN
당시에는 유명했던 네트워크는 VGG-16 이었다. 네트워크에 대한 설명은 [여기]를 참조. K40 GPU를 사용해서 5천장의 이미지를 학습시키는데, 2.5일이 걸렸다고 한다.
3. ROI(Region of Interest) Polling
Fast RCNN에서는 이미지를 CNN에 넣은 후 Crop을 진행하기 때문에, 각각의 Crop Size가 모두 다르다. 위 그림의 초록색 FeaturMap을 보라. Crop Size가 모두 다른것을 알 수 있다. 이것은 고정된 길이의 Feature Vector로 변환할 수가 없다는 문제점이 발생한다.
이게 왜 문제인가 하면, 선형대수적인 문제로써 행렬의 형상이 다르기 때문에 Crop FeatureMap들끼리 concat할 수 없다는것이다. 이러한 문제점을 해결한 방법이 바로 ROI Polling이다. 이 단계를 거치면 각기다른 Size가 동일한 형상으로 변하게 된다. 자세한것은 Appendix 참고.
4. Multi-Task Loss
RoI Pooling을 통과한 동일한 크기의 Feature Map은 두개의 브런치로 나뉘어 Classification과 bbox regression에 사용된다. Classification에서는 더이상 SVM을 사용하지 않고 신경망에서 Classification을 수행한다. 사용된 손실함수는 log loss이다. bbox regression의 손실함수는 RCNN에서 사용했던 L2 Loss 방법을 사용하지 않고 L1 Smooth Loss로 변경되었다.
이렇게 2개의 브런치에서 2개의 Loss가 나오게 되는데 이것을 더하여 Total Loss를 만들었다. 그래서 Multi-Task Loss인 것이다. 자세한 내용은 Appendix를 참조.
Result
RCNN에 비해서 속도는 학습시간은 9배 정도 향상되었으며 추론시간은 무려 213배 향상되었다고 한다. PASCAL VOC 2007 데이터셋 기준으로 mAP는 66%에서 70% 까지 상승되었다.

저자는 속도향상의 원인은 세가지라고 말한다.
- Selective Search와 CNN의 순서를 바꿈으로써 연산량을 획기적으로 줄임.
- 역전파를 이용하여 End-to-End 학습이 가능해졌다는것.
- SVD(Sigular Vector Decomposition). 우리말로는 특이값 분해라는 단어이다. FC Layer의 가중치를 계산할때 적용하여 연산량을 상당히 줄일 수 있었다고 한다.
Fast R-CNN은 R-CNN에서의 문제점을 획기적으로 수정하면서 보다 개선된 모델이다. 하지만 Selective Search는 여전히 병목중 하나였고 Network에 포함되어있지 않는 독립적인 모듈이기 때문에 진정한 End-to-End는 아니었다. 여전히 Fast RCNN은 문제가 있다.
Appendix
ROI(Region of Interest) Polling
RoI는 (r,c,h,w)의 좌표 형태로 표현된다. (r,c)는 좌상단의 꼭지점 좌표이고 (h,w)는 높이와 너비이다. 고정된 크기 (H,W)의 Feature Map으로 변환하고자 한다면, $\frac{h}{H} \times \frac{w}{W}$ 의 Grid를 만들어준 후 Max-Pooling을 하면 (H,W)의 크기를 가지는 Feature Map으로 변환된다.
Example
아래와 같은 상황을 고려해보자. Conv Layer들을 거쳐서 아래와 같이 8x8 크기의 Feature Map이 있다.

해당 이미지에서 RoI를 찾아서 하나의 좌표를 얻는다. (x,y,h,w)=(0,3,5,7)이 되는 어떠한 RoI이다.

이 RoI를 RoI Pooling Layer를 거쳐 2x2의 고정된 크기의 Feature Map을 만들고자 한다. 따라서 $\frac{5}{2} \times \frac{7}{2} = 2 \times 3$의 Grid를 만들어 준다. 여기서 정수가 나오지 않고 소수점이 나오면, 반올림 또는 버림을 하여 Stride를 조정해준다. Stride는 Grid의 크기와 항상 똑같이 이동한다.

각각의 Cell에서 Max Pooling을 시행해주면 최종적으로 아래와 같은 고정된 크기의 Feature Map을 구할 수 있다.

Multi-task loss
Classification에서 사용되는 손실함수는 Log loss를 사용하며 그 식은 아래와 같다.
$$
L_{cls}(p, u) = -log(p_{u}), \qquad where \; u \; is \; true \; class
$$
bbox regression에서 사용되는 손실함수는 L1 Smooth Loss를 사용하며 그 식은 아래와 같다.
$$
L_{loc}(t^{u},v)=\sum_{i\in{x,y,w,h}}(smooth_{L1}(t_{i}^{u}-v_{i}))
$$
$$
Where, \;
smooth_{L1}(x) =
\begin{cases}
0.5x^2\qquad if \quad|x| < 1\\
|x| - 0.5 \qquad otherwise\\
\end{cases}
$$
L1 Loss는 오차가 $\pm1$ 안쪽에 있다면 제곱의 형태를 손실함수로 사용하며, 그렇지 않을 경우에는 1차함수를 손실함수로 사용한다. 이렇게 함으로써 Outlier에 보다 강건하게(Robust) 적합을 시킬 수 있다. 이제 위 두개의 Loss를 단순히 더하기만 하면 Multi-task Loss가 완성된다.
$$
L(p, u, t^{u}, v) = L_{cls}(p,u) + \lambda[u\geq1]L_{loc}(t^{u},v)
$$
여기에서 $\lambda$는 두 Loss를 합치면서 발생하는 불균형을 조절하는 상수이다. 딱히 정해진 값은 없으며, 논문에서는 1을 사용하였다. $\lambda$ 뒤에 붙어있는 $[u\geq1]$의 의미는, 배경(Background)일때 0이고 배경이 아닐때(Not Backgound) 1이 된다는 기호이다. 이 기호를Iverson bracket indicator function이라고 부른다. Multi-Task Loss의 개념은 이후에 나오는 모든 Detection, Segmentation에서도 활용되는 아이디어니 참고하길 바란다.







최근댓글