R-CNN, Fast R-CNN에서 Region Proposal을 구하는 방법은 Selective Search를 통해 구했다. 하지만 이 방법은 CPU를 통한 연산이었으며 신경망에 포함되어있지 않았다. 따라서 모든 Pixel에 대해서 연산을 하고 병합을 해야하기 때문에 가장 큰 병목이었다.
Faster R-CNN은 이러한 병목을 해결하였으며, 논문의 제목답게 Faster R-CNN Towards Real-Time Object Detection with Region Proposal Netwoks로써 실시간 탐지가 가능하였다. 이 병목을 어떻게 해결하였을까??
Concept
Faster R-CNN은 두가지 모듈로 구성이 되어있다.
- Region Proposal을 만드는 영역.(RPN)
- Fast R-CNN 영역.
신경망이 두개의 모듈을 포함하고 있기 때문에, 모듈간 FeatureMap의 연결을 어떠한 방법으로 할것인지도 고려해야한다. 논문에서는 3가지 방법을 제안하였다.
- Alternating training.
- Approximate joint trainning
- Non-Approximate joint tranning

1. Region Proposal Networks(RPN)
Faster R-CNN의 가장 큰 특징은 Anchor Box 개념을 도입하여 기존 SS를 대체하였으며, Region Proposal을 신경망에 포함시켰다는 것이다. Anchor Box는 사각형 모양의 Box를 이미지의 모든 픽셀들을 검색하는 slinding window방식으로 해당 위치의 정보를 탐색하는 방식이다.
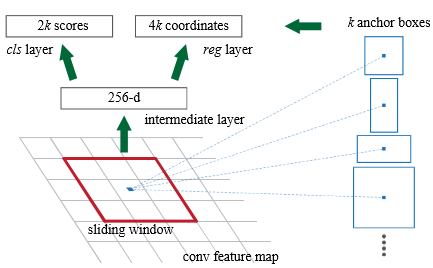
Anchor Box는 scale, Aspect Ratio가 각기 다른 k개의 Anchor Box가 있다. Faster R-CNN에서는 Scale : (128, 256, 512), Aspect Ratio : (2:1, 1:1, 1:2)를 사용하여 총 9개의 Anchor Box를 생성하였다. 각각의 픽셀을 훑어나갈때 Stride를 1로 하면 더욱 정확한 결과를 얻을 수 있지만, 이는 많은 연산량이 부담이 될 수 밖에 없다. 따라서 Stride는 10 이내에서 결정하였다.
위 그림은 256차원의 Feature Map로부터 Anchor Box를 Sliding Window하는 예시이다. 우선 Anchor Box의 영역이 객체인지 아닌지를 추정하는 cls layer와 각 좌표값을 추정하는 reg layer 두가지로 브런치 해야한다. Anchor Box는 9개를 사용하기 때문에 $256 \times (4+2) \times 9$ 만큼의 Parameter가 생성이 된다. 4는 4개의 좌표를 의미하고 2는 객체인지 아닌지를 뜻한다.
이 방법은 기존 SS의 방법보다 Parameter의 수가 상당히 줄일 수 있으며 연산량도 빨라지고 Anchor Box자체가 Spartial하기 때문에 Overfitting에 대한 위험도 피할 수 있다. 또한 신경망 내부에서 역전파를 통해 연산을 수행하게 되므로 Bounding Box Regression을 매우 빠르게 수행할 수 있으며 GPU연산도 가능하게 되었다.
그림에서도 보듯이 Classification Layer와 Regression Layer가 존재하기 때문에 가중치를 업데이트 하기 위해서는 손실함수가 필요하다. 여기서 사용하는 손실함수는 아래와 같다.
$$
L({p_{i}}, {t_{i}}) = \frac{1}{N_{cls}}\sum_{i}L_{cls}(p_{i}, p{i}^{}) + \lambda\frac{1}{N_{reg}}\sum_{i}p_{i}^{}L_{reg}(t_{i},t_{i}^{*})
$$
Classification Loss에서는 RoI가 객체인지 객체가아닌지(즉, 배경) 추정하며, Regression Loss에서는 좌표값은 추정하게 된다. 자세한 내용은 Appendix 참조
2. Fast RCNN
RPN을 수행한 후 넘겨받은 좌표값을 활용하여 ROI Pooling을 수행하고, Classification과 Box Regression을 수행한다. 기존 Fast R-CNN에서 하던 방법과 동일하게 동작한다. 즉, 여기에서도 손실함수가 등장한다.
$$
L(p, u, t^{u}, v) = L_{cls}(p,u) + \lambda[u\geq1]L_{loc}(t^{u},v)
$$
여기까지 읽어보면 무언가 헷갈리는점이 발생한다. RPN에서도 Loss Function이 존재하고, Fast RCNN에서도 Loss Function이 존재한다는 점이다. 전혀 이상한것이 아니다. 왜냐하면 이것은 네트워크가 2개이기 때문이다. RPN영역 + Fast RCNN 영역을 하나로 묶어서 Faster-RCNN이라고 부른것이므로 각각의 영역에서 Loss Function이 존재하는것은 당연하다. 때문에 Two-Stage 모델이라고 부른다.
3. Sharing Features for RPN and Fast R-CNN
RPN과 Fast R-CNN 두 네트워크를 독립적으로 학습을 진행하는것이 아닌라 convolutional layers를 공유하는 형태로 학습을 진행하게 된다.
1. Alternating training.
우선 RPN 학습을 진행한다. 획득한 Proposals로부터 Fast R-CNN을 학습한다. Fast R-CNN의 학습이 끝난 후 Bouding Box Regression을 통해 수정된 좌표값을 통해 RPN의 좌표값을 초기화한다(Update). 그리고 이 과정을 반복한다. 논문에서는 이 방법으로 모든 실험을 진행하였으나 과정이 복잡하여 더이상 사용하지 않는 방법이다.
2. Approximate joint trainning
RPN와 Fast R-CNN 네트워크를 하나의 네트워크로 병합한다. 순전파 진행시 RPN으로 부터 획득한 좌표값을 Fast R-CNN 영역에 좌표정보를 전달해주게 된다. 넘겨받은 좌표정보를 이용하여 Fast R-CNN의 학습이 진행된다. Loss의 계산은 Fast R-CNN Loss와 RPN Loss를 동시에 계산하여 병합된 Loss를 구한다.
Alternating training과 달리 두개의 모듈이 병합된 형태이기 때문에, 모든 Layer에 가중치를 공유하게 된다. 1번 방법보다 25~50%가량 학습 속도를 단축시켰다고 한다.(Pytorch 내부 코드 형태)
3. Non-Approximate joint training
Approxtimate joint traning의 방법은 Bounding Box 좌표를 고정된 값(상수) 형태로 Fast R-CNN에 넘겨주기 때문에 정확한 값을 얻을 수 없다. RPN으로부터 예측한 Bounding Box 좌표는 상수가 아니라 함수이기 때문에, 역전파를 할 때 Bounding Box 좌표에 대한 값을 미분을 활용하여 업데이트 하는것이 이론적으로는 정확하다.
이 방법을 적용하기 위해서는 Bounding Box 정보를 Fast R-CNN영역과 주고받는 Layer가 필요한데, 이를 ROI Warping layer라고 부른다. 논문에서는 이론적인 방법만 제시하였으며 테스트를 해보지는 않았다.
Result
SS는 CPU로 연산처리를 할 수 밖에 없지만 RPN은 GPU로 작업이 가능하기 때문에 상당한 fps를 보여준다. RP의 수도 상당히 줄었음에도 mAP는 보다 증가되었음을 보여준다. PASCAL VOC 2007 데이터셋으로는 73.2%의 mAP와 이미지당 198ms(약 0.2s)의 Inference Time을 내었다고 한다.


Appendix
Anchor Box
RPN을 학습하기 위해서 각각의 Anchor Box에 대하여 객체 인지 아닌지를 나타내는 binary class label을 달아줘야 한다. 방법은 간단하게 Ground-Truth Box와 IOU를 계산하고 두가지 조건을 체크해주기만 하면 된다.
Positive sample(객체다!)
- Anchor Box와 GT의 IOU가 가장 높은 Anchor
- Anchor와 GT의 IOU가 0.7이상인 Anchor
Negative sample(배경이다!)
- Anchor와 GT의 IOU가 0.3이하인 Anchor
IOU가 0.3 ~ 0.7 사이인 Anchor는 제외하기로 한다. 해당 영역에서는 Labeling을 해주기가 애매하기 때문이다.
Positive Label은 해당 Anchor Box가 객체라는것을 뜻하며, Negative Label은 배경을 의미한다. 이렇게 Label을 달아주었다면, RoI Pooling을 시행하여 Feature Map의 size를 동일하게 만들어준 후, Multi-task loss를 이용한다.
$$
L({p_{i}}, {t_{i}}) = \frac{1}{N_{cls}}\sum_{i}L_{cls}(p_{i}, p{i}^{}) + \lambda\frac{1}{N_{reg}}\sum_{i}p_{i}^{}L_{reg}(t_{i},t_{i}^{*})
$$
i는 위에서 적어놓은 조건을 만족한 Positive, Negative Label의 갯수이다. Positive sample일 경우 $p_{i}^{\ast}$ 는 1, Negative일 경우에는 0이 된다. $t_{i}$ 는 예측한 4개의 Bounding Box 좌표를 의미하고, $t_{i}^{\ast}$ 는 GT의 좌표를 의미한다.
$L_{cls}$는 log loss이고 $L_{reg}$는 smooth L1 Loss이다. 또한 $L_{reg}$ 텀에 $p_{i}^{\ast}$가 곱하기로 붙어있는것으로 보아 Positive sample일 경우에만 Loss가 존재하게되고 Negative sample일때 Reg Loss는 0이 된다는것을 알 수 있다. 다시말하면, Negative sample(배경)일 경우에는 $L_{reg}$의 Loss자체가 0이 되버려 가중치 업데이트에 영향을 주지 않게되는 구조이다.
각각의 텀 앞에 붙어있는 $N_{cls}, N_{reg}$는 정규화를 하기위한 것이다. 해당 논문에서는 mini-batch size가 256이므로 $N_{cls}=256$이 되고, Anchor의 갯수가 약 2400개 이므로 $N_{reg}=2400$이 된다. $N_{reg}$텀 앞에 붙어있는 $\lambda$를 10으로 저정해주면 대량 256에 근사한 값을 가지게 됨으로써, $L_{cls}, L_{reg}$ 두 텀의 균형이 맞춰지게 된다.
Number of Anchor for training step
학습을 진행할때 Anchor Box가 몇개나 생성이 될까? 논문에서 학습의 과정을 다음과 같이 설정을 하였다.
- 이미지의 W, H중 작은 쪽의 길이가 600이 되도록 re-size를 해준다.
- CNN의 마지막 conv layer의 Sliding Window stride는 16을 설정하였다.
- Anchor Box의 Scale : (128, 256, 512) Aspect ratios : (1:1, 1:2, 2:1)
일반적으로 1000x600으로 re-size된 이미지에 대하여 Sliding Window의 stride가 16이므로 $W=1000/16=62.5$이고 $H=600/16=37.5$가 되므로 약 $60 \times 40 \times 9 = 20000$ 개의 Anchor가 생성된다. 이미지의 경계부분을 살펴보면 Anchor Box가 가로질러나가는 것이 존재하는데, 이를 cross-boundary anchor라고 부른다.
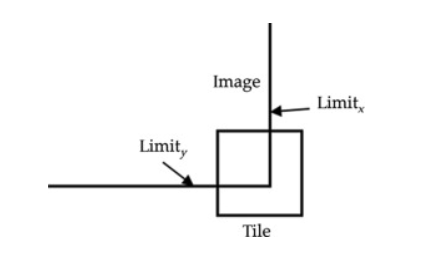
학습을 할때에는 해당 영역이 Loss에 기여하지 못하므로 이 부분은 제외해주어야 한다. 이러한 부분을 제거해주면 남아있는 Anchor는 약 6,000개가 된다.
마지막으로 쓸데없이 겹치는 Anchor들이 상당히 많은데, 이것을 감소시키기 위해서 IOU가 0.7 이상인 조건하에서 NMS를 적용한다. 여기까지 진행하여 약 2000개의 Anchor가 완성되게 된다(NMS를 조절하면 2000개보다 훨씬 적은 Anchor가 만들 수 있으며, 추론을 진행할때는 300개의 Anchor만 추출하였다).
Loss를 계산할때는 2000개의 Anchor중에서 256개의 Anchor만 선택하게 된다. 256이 튀어나온 이유는 mini-batch size가 256이기 때문이다. 128개는 Positive sample로, 128개는 Negative sample에서 1:1비율로 선정한다. 만약 Positive Anchor가 128개가 안된다면, Negative Anchor를 추가하게된다. 그러나 현실적으로 Positive sample의 수는 압도적으로 적은것이 일반적이다. 이 방법을 보완하기위해 후에 Focal Loss가 등장하였다.







최근댓글