YoLo는 가장 많이 사용되는 One-Stage 알고리즘으로 많은 사람들에게서 사랑받고있다. R-CNN 계열의 Two-Stage 알고리즘과 달리 분류(Classification)와 좌표추정(Regressor)를 한번에 처리하기 때문에 매우 빠른 속도를 보장한다. You Only Look Once(YoLo)라는 이름은 이미지를 한번에 모든 추론과정을 수행하기 때문에 부여했다고 한다.
Concept
YoLo를 이해하기 위해서는 전체적인 구조를 살펴보아야 한다.

입력 이미지를 448x448로 resize하고 CNN 신경망을 거쳐서 내려가기 시작한다. 총 24개의 Conv Layer를 거쳐내려간 후, 2개의 FC Layer를 추가한다. 마지막 FC Layer에서는 7x7x30이 되도록 reshape를 진행한다. 30개의 채널은 각각이 의미하는 값으로 채워져있다. 이 30이라는 의미에 대해서 하나씩 알아보도록 하자.
Confidence
우선 Confidence에 대한 개념은 Faster-RCNN에서 다뤘었던 RPN을 잠시 떠올려보는것으로 시작한다. RPN에서는 해당 ROI가 객체인지 아닌지를 나타내는 여부를 Positive Sample, Negative Sapmle로써 표현하였다. 이러한 개념과 유사하게 YoLo에서는 해당 ROI가 객체인지 아닌지를 신뢰도의 수치로 표현한다. 이것이 Confidence이다.
$$
Confidence = Pr(Obj) \ast IOU^{truth}_{pred}
$$
YoLo v1에서는 최종 Feature Map의 모든 Grid cell 각각을 모두 ROI라고 판정하여 검사를 진행한다. 만약 특정 grid cell에 객체가 존재하지 않으면 $Pr(Obj)=0$이 되어 confidence는 0이 될것이다. 반면 객체가 존재한다면 $Pr(Obj)=1$이 된다.
객체의 존재여부는 Ground Truth Box 내부와 외부로 판단한다. 즉, 객체가 존재할때 Confidence는 IOU와 같은 값이라고 볼 수 있으며, Box Regression을 성공적으로 잘 했다고 판정할 수 있을것이다.
Bounding Box Coordinate
각각의 Grid cell에서는 2개씩 Bouding Box를 예측한다. 아래 그림의 노란색 Box는 Grid cell을 의미한다. 자전거를 타고있는 사람의 예시 사진을 통해 자세히 알아보자.
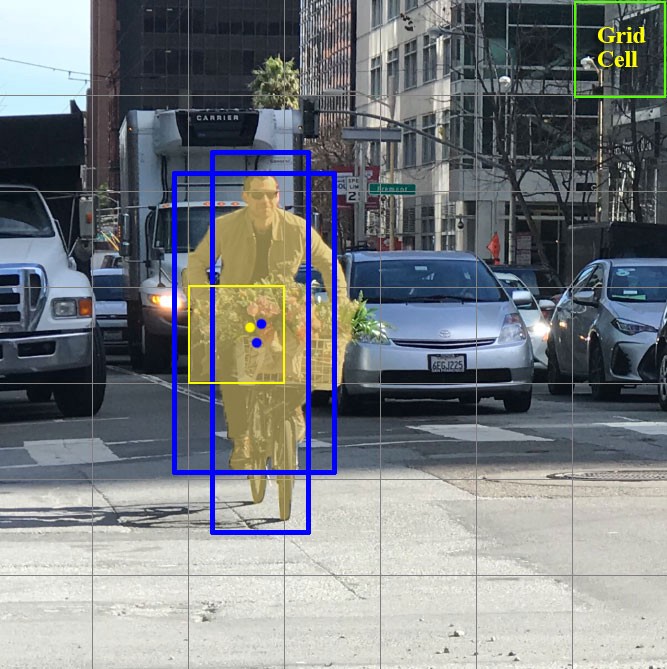
우선, 해당 Grid Cell에서 2개의 파란색 Box가 존재한다. 파란색 Box는 가로 세로비(Aspect Ratio)가 다르기 때문에 중심점도 다르다는것을 알 수 있다. 노란색 점은 Ground Truth(GT)의 중심을 나타낸다. YoLo에서는 이전에 배웠었던 개념과는 다르게 좌표값을 정규화한다.
파란색 Box의 중심은 노란색 Box를 기준으로(즉, Grid cell을 기준으로) 정규화된다. 예를들어 파란색점은 각각 (x, y) = (3.8, 4.4), (3.7, 4.6) 정도로 표현할 수 있을것이다. 그림의 전체 이미지 size는 7x7이므로 (x, y) = (3.8/7, 4.4/7), (3.7/7, 4.6/7) = (0.54, 0.63), (0.53, 0.66)으로 정규화된다.
width와 height의 표현은 전체 이미지를 기준으로 정규화한다. 예를들어 파란색 Box의 w, h는 각각 (1.5, 3.2), (0.9, 3.9)정도 되보인다. 위와같이 계산을 해보면 (w, h) = (1.5/7, 3.2/7), (0.9/7, 3.9/7) = (0.2, 0.4), (0.12, 0.55) 정도로 표현할 수 있을것이다.
그림에는 나와있지 않지만, 노란색 점을 중심으로한 빨간색의 GT Box가 있다고 상상해보자. 빨간색과 파란색 Box의 대략적인 IOU를 각각 (0.8, 0.6) 정도라고 한다면, 이제 Confidence도 구할 수 있다. 노란색 Box의 Grid cell은 GT Box 내부에 있기 때문에 $Pr(Obj)=1$이다. 즉 Confidence는 GT와 파란색 Box와의 IOU인 (0.8, 0.6)이된다.
최종적으로 이를 하나의 표현으로 써보면 (x, y, w, h, c) = (0.8, 0.4, 0.2, 0.4, 0.8), (0.7, 0.6, 0.4, 0.55, 0.6) 이 되게된다. YoLo로 되어있는 annotation파일을 살펴보면 좌표값이 모두 0~1 사이로 정규화되어있는데, 바로 이러한 이유때문이다.
classification score
이번에는 해당 Grid Cell에서 class 확률을 구해야한다. 산식은 아래와 같다.
$$
Pr(Class_{i} \vert Obj)
$$
$Pr(Obj$)가 1일때는 Grid Cell의 $Pr(Class_{i} \vert Obj)$를 랜덤하게 초기화 하고(정확히는 랜덤하게 초기화된 Conv Layer를 통해 초기값을 획득), $Pr(Obj)$가 0일 경우에는 0으로 처리하여 학습을 시작한다. 테스트(추론)를 할때에는 $Pr(Class_{i} \vert Obj)$에 Confidence를 곱한 형태의 산식을 적용한다.
$$
class \; scores = Pr(Class_{i} \vert Obj) \ast Pr(Object) \ast IOU^{truth}{pred} = Pr(Class{i}) * IOU^{truth}_{pred}
$$
이렇게 산식이 변경되는 이유는 Confidence를 곱함으로써 Clasification과 Box Regression을 종합적으로 고려하여 Score를 계산하기 위함이라고 한다. 논문에서 사용한 PASCAL VOC의 class갯수는 20개이기 때문에, Grid Cell당 class scores의 갯수는 20개씩 존재한다.
종합적으로 정리해자. 1개의 Grid cell에는 2개의 Bounding Box가 존재한다. 각 Box에는 4개의 좌표값과 1개의 Confidence Score가 있으므로 x2를하여 총 10개의 채널이 존재한다. 마지막으로 classification score가 class의 갯수만큼 존재하므로 20개의 채널이 더해져서 (4+1)*2+20=30 이란 값이 등장하게 되는것이다.
Loss Function
위에서 설명한 내용에 근거하면 알아야할 파트는 크게 3가지가 있다. Bounding Box파트, Confidence파트, Class Score파트이다. 자연스럽게 Loss는 각각의 파트에 대하여 계산을 하게 된다.
Localization Loss
$$
\lambda_{coord}\sum_{i}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{i,j}^{obj}\left[(x{i} - \hat{x_{i}})^{2} + (y_{i} - \hat{y_{i}})^{2} \right] + \\ \lambda_{coord}\sum_{i}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{i,j}^{obj}\left[(\sqrt{w{i}} - \sqrt{\hat{w_{i}}})^{2} + (\sqrt{h_{i}} - \sqrt{\hat{h_{i}}})^{2} \right]
$$
이미지에는 물체가 포함된 Box보다 그렇지 않는 Box(즉, Background)가 더 많기 때문에 Error를 계산할때 불균형이 일어날 수 있다. $\lambda$는 이를 해결하기 위한 상수이다.
물체가 포함된 영역의 grid cell에는 $\lambda_{coord} = 5$를, 그렇지 않은 영역에는 $\lambda_{noobj} = 0.5$를 곱하여 Backgroud와 객체의 불균형을 개선한다. 좌표값을 구하는것은 객체가 존재하는 영역에서만 계산을 하면 되기 때문에, Localization Loss에는 $\lambda_{noobj}$ 가 존재하지 않는다.
$\mathbb{1}_{i,j}^{obj}$은 i번째 grid cell에서 j번째 Bounding Box에 물체가 존재할 경우를 나타내며 만약 존재한다면 1, 그렇지 않으면 0으로 표현한다.
Confidence Loss
$$
\sum_{i}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{i,j}^{obj} \left(C{i} - \hat{C_{i}}\right)^{2} + \lambda_{noobj}\sum_{i}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{i,j}^{noobj}\left(C{i} - \hat{C_{i}}\right)^{2}
$$
$\hat{C_{i}}$는 Confidence 즉, $Pr(Object) \ast IOU^{truth}_{pred}$를 나타낸다. i번째 grid cell에서 j번째 Bounding Box에 물체가 존재할때, 앞쪽의 Loss만 살아남고 뒤쪽은 0이 된다.
반대로 물체가 존재하지 않으면 앞쪽의 Loss는 0이되고 뒤쪽의 Loss만 살아남게 된다. 이때 $\lambda_{noobj} = 0.5$를 곱해준다.
Classification Score Loss
$$
\sum_{i}^{S^{2}}\mathbb{1}_{i,j}^{obj}\sum_{c \in classes} (p_{i}(c) - \hat{p_{i}}(c))^{2}
$$
$\hat{p_{i}}(c)$는 grid cell에 물체가 존재할때, class c가 들어있을 확률, 즉 $P(class_{i}\vert object)$ 이다. Localization, confiden와 마찬가지로 i번째 grid cell에서 j번째 Bounding Box에 물체가 존재할때, classification loss를 계산하며, 그렇지 않을때는 0이 된다.
Multi Loss
이제 3가지 파트에 대하여 Loss를 더해주기만 하면 된다.
$$
\lambda_{coord}\sum_{i}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{i,j}^{obj}\left[(x{i} - \hat{x_{i}})^{2} + (y_{i} - \hat{y_{i}})^{2} \right] + \\
\lambda_{coord}\sum_{i}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{i,j}^{obj}\left[(\sqrt{w{i}} - \sqrt{\hat{w_{i}}})^{2} + (\sqrt{h_{i}} - \sqrt{\hat{h_{i}}})^{2} \right] + \\
\sum_{i}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{i,j}^{obj} \left(C{i} - \hat{C_{i}}\right)^{2} + \lambda_{noobj}\sum_{i}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{i,j}^{noobj}\left(C{i} - \hat{C_{i}}\right)^{2} + \\
\sum_{i}^{S^{2}}\mathbb{1}_{i,j}^{obj}\sum_{c \in classes} (p_{i}(c) - \hat{p_{i}}(c))^{2}
$$
Loss Funcfion은 객체가 해당 Grid cell에 있는 경우에만($Pr(obj)=1$) Classification Score에 페널티를 준다. Box Regression에 대해서도 마찬가지로 $Pr(obj)=1$인 경우에만 패널티가 부과되는것을 알 수 있다.
이러한 방법을 통해 Loss를 줄이는 방향으로 역전파가 진행되고 가중치가 업데이트를 하게된다.
Result
PASCAL VOC 2007과 2012 데이터셋을 합쳐서 학습시킨 결과, YoLo는 63.4% mAP 45FPS를 보여주었다. Two Stage method인 Faster R-CNN이 mAP 73.2%와 7FPS 라는 수치와 비교해보았을때, 정확도는 조금 떨어졌지만 6배가 넘는 FPS 수치를 보여주며 실시간 탐지의 지평을 열게 되었다.
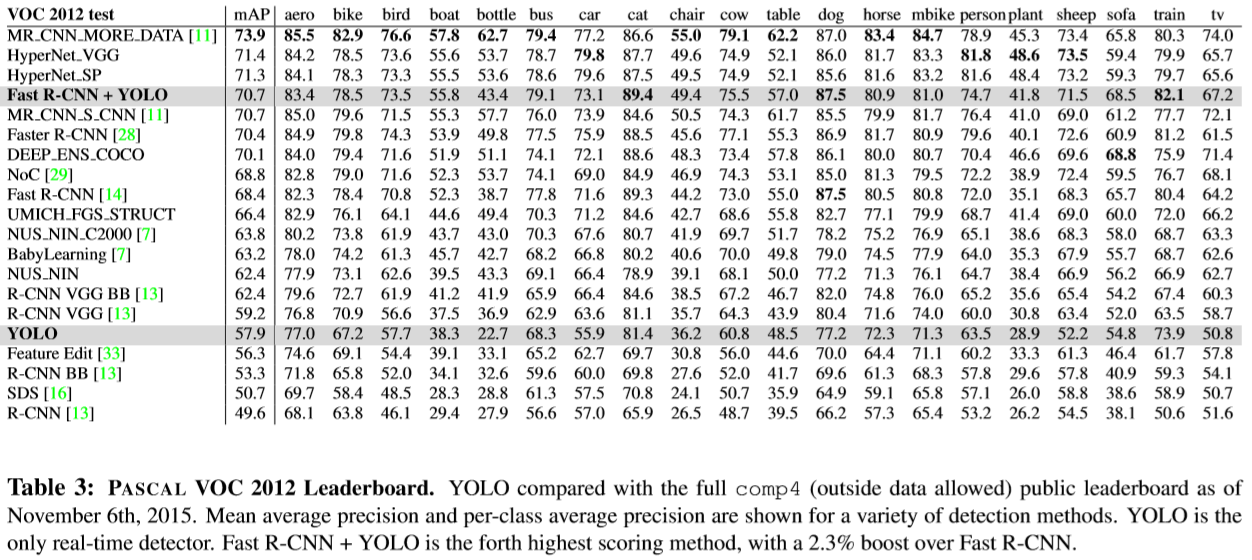
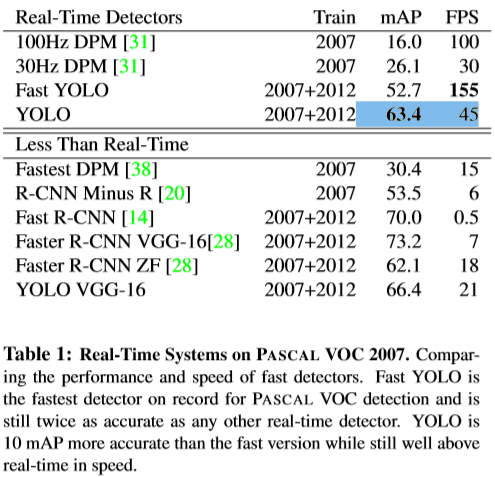
하지만 YoLo는 각 grid cell마다 2개의 bounding box밖에 없다. 또, grid cell당 단 한가지의 class만을 가진다. 그렇기 때문에 물체가 너무 작아 하나의 grid cell에 여러개가 겹치는 경우에는 제대로 탐지를 하지 못한다는 단점이 있다.

YoLo v1은 탐지영역과 분류영역을 통합한 모델로써, 45FPS의 실시간에 가까운 추론을 해내며 정확도 또한 일정 수준 이상 보장해주는 아주 훌륭한 One Stage mothod로 자리잡았다.
하지만 작은 객체는 잘 탐지해내지 못한다는점과, grid cell이 7x7로 고정된다는 점은 좋지 못한 결과를 보여주었다. 연구자들은 이러한 단점을 하나씩 보완해나가기 시작하였고 YoLo v2가 등장하게 되었다.
Appendix
YOLO v1에 대한 자세한 내용은 deepsystem에서 추가적으로 확인하길 바란다.
해당 슬라이드는 코가 막힐정도로 이해하기 쉽고 시각적인 설명이 잘 되어있다. 필자가 쓴 이런 허접한 필력으로써는 따라갈 수 없기 때문에 반드시 한번은 보는것을 추천한다.







최근댓글