XNOR-Net은 2016년에 출시된 논문으로 가중치 양자화에 대한 컨셉에 대해서 소개를 하는 논문이다. 이전에 소개했던 DoReFa-Net보다도 앞서 발표되었으며, 이후 QAT(Quantization Aware Training)계열의 양자화 기법에 개념적 부분으로 많이 사용되고 있다. 논문에서는 가중치를 1-Bit 양자화하는 BWN(Binary-Weight-Net)과 가중치와 활성화출력 두가지를 모두 1-Bit 양자화하는 XNOR-Net 두가지를 모두 소개하고 있다.
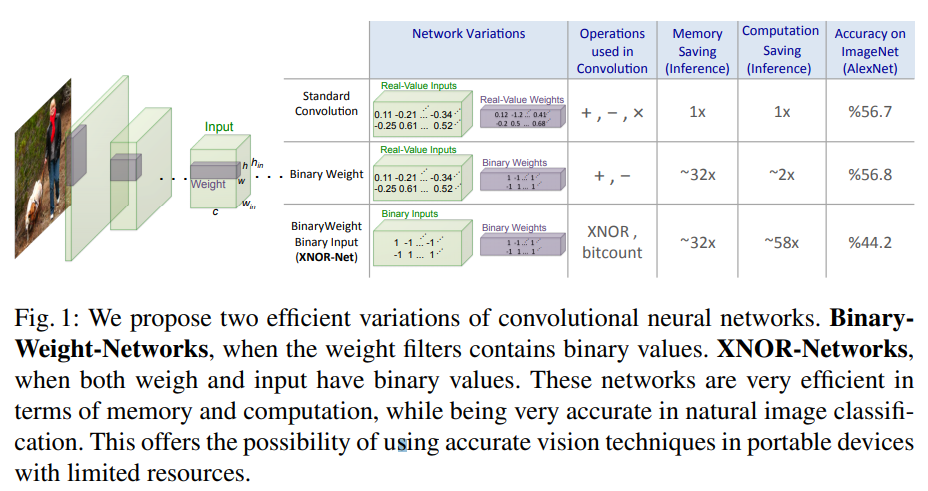
Binary Weigth Network
이전 Feature Map에서 나온 입력값을 $I$라고 하고, 양자화 되기 전 Conv Layer를 $W$라 하자. 다음으로 가중치에 대하여 이진화된 Conv Layer를 $B$ 라고 해보자. 이진화에 사용되는 함수는 $Sign(x)$를 사용한다. 기존의 컨볼루션 연산은 $I \ast W$가 될것이며, 이진화된 가중치와 연산을 하게 되면 $I \ast B$가 되게 된다. 하지만 $I \ast W \neq I \ast B$가 아니다. 그래서 특정 Scaling Factor $\alpha$를 도입하면 아래와 같이 좌변과 우변의 값이 근사할 수 있을것이다.
$$
I \ast W \approx (I \oplus B)\alpha
$$
$\oplus$기호는 $B$는 이미 이진화가 된 값이기 때문에 Input과 곱하기 연산을 할 필요가 없는 컨볼루션 연산기호로 정의한다. 위 산식으로 부터 $W-\alpha B$의 차이가 양자화 오류라는것을 알 수 있을것이다. 이제 이 오류를 최소화 하는 지점의 $\alpha$를 찾기만 하면된다. 최소제곱법을 통해서 $\alpha$의 최적값을 추정해보면 가중치 절대값의 평균이 된다고 한다.
$$
\alpha^{*} = \frac{W^{T}sign(W)}{n} = \frac{\sum |W_{i}|}{n} = E(|W_{i}|)
$$
가중치의 업데이트는 양자화 되기 전 가중치인 $W$에 대해서 업데이트를 하게 된다. 따라서 앞쪽 레이어로부터 역전파된 $W$의 기울기를 알아야 한다. 하지만 순전파는 양자화가 된 상태이기 때문에 $B$의 기울기를 알게되는 셈이다. 즉, $B$와 $W$의 관계에 대해서 한번 더 전개를 해야한다.
$$
W^{t+1} = W^{t} - \eta \frac{\partial C}{\partial W^{t}} \
\frac{\partial C}{\partial W^{t}} = \frac{\partial C}{\partial \tilde W} \frac{\partial \tilde W}{\partial W^{t}} \
\frac{\partial \tilde W}{\partial W^{t}} = \frac{1}{n} + \frac{\partial sign(W_{i})}{\partial W_{i}}\alpha
$$
여기서 $\frac{\partial \tilde W}{\partial W^{t}}$는 $\frac{\partial \alpha B}{\partial W^{t}}$라고 할 수 있고, $\alpha B$에 대해서 미분을 진행하면 위와 같은 식을 얻을 수 있다. 아래는 순전파, 역전파 그리고 가중치 업데이트에 대한 순서를 적어둔 표이다.

XNOR_Network
BWN에서는 가중치만 양자화를 진행하였다면 여기서는 이전 Layer로 부터 받은 FeatureMap에 대해서도 양자화를 진행한다. 방법은 가중치를 양자화한 방법과 똑같이 진행이 된다. 여기에서 $\odot$은 Bit-Wise Operation을 의미한다.
$$
\alpha^{*} = \frac{W^{T}sign(W)}{n} = \frac{\sum \vert W_{i} \vert}{n} = E(\vert W_{i}\vert)
$$
논문의 저자는 여기서 연산에 대한 비효율성을 하나 발견하게 된다. 위 그림에서 (2)를 보면, Conv Layer가 설정된 Stride만큼 이동하면서 연산이 되는 영역을 각각 $X_{1}, X_{2}, ...$로 둔다. 연산이 되는 영역마다 양자화를 진행해주게 되므로, 양자화된 $H_{1}, H_{2}, ...$와 더불어 Scale Factor인 $\beta_{1}, \beta_{2}, ...$를 얻을 수 있다. 그런데 이 방법은 중간에 윈도우가 중첩되는 영역에서 양자화를 반복진행한다는 비효율을 발견한 것이다.
이것을 해결하기 위해 (3)과 같이 입력 FeatureMap에 대해서 양자화를 진행한후 모든 값을 더하여 채널갯수만큼 나누어 준다($\frac{\sum|I_{:,:,i}|}{c}$). 이렇게 만들어진 FeatureMap을 $A$라고 한 후, Conv Layer의 width, height의 크기를 가진 filter $k$를 만들어준다. $k$가 가지는 값을 $\frac{1}{w \times h}$로 설정하게되면, $A \ast k = K$로 표현할 수 있다. $K$는 중복되지 않은 연산을 하기위한 $\beta$의 또다른 표현이다. 이제 최종적으로 (4)와 같이 계산을 해주면 된다. $\circledast$는 XNOR Bitcount Operation을 의미하며, $\odot$은 행렬의 내적을 의미한다.
$$
I*W \approx (sign(I) \circledast sign(W)) \odot K\alpha
$$
XNOR-Net의 의미는 여기서부터 유래했다. 맨 위의 그림에서 보듯이 컨볼루션 연산은 +, x 로 이루어져 있는반면, Feature Map과 Conv Layer가 모두 이진 양자화 되어있기 때문에 XNOR 연산을 한다는 뜻이기 때문이다. 저자가 주장하기를 양자화하기 전 컨볼루션 연산대비 약 58배 가량 속도개선이 있었다고 한다.
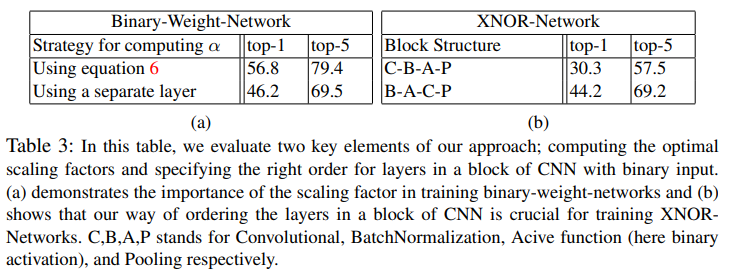
학습을 진행할때는 이것뿐만 아니라 Block 내부의 Layer순서에 따라 매우 결과가 다르게 나타난다고 한다. 위 그림의 왼쪽처럼 일반적인 CNN구조에 XNOR-Net을 적용하게되면, Activation을 거쳐 나온 FeatureMap을 양자화 진행한 후 Max-Pooling을 하는 형태가 된다. 이러한 구조는 상당히 많은 정보의 손실을 초래하게 된다. 그래서 저자는 이러한 정보손실을 최소화 하고자 Conv Layer를 Pooling Layer 앞으로 배치하였다고 한다.

Result
실험은 BWN, XNOR-Net을 적용한 AlexNet 모델과 ResNet모델 2가지로 ImageNet 데이터셋으로 실험을 진행하였다. 메모리 사용량과 속도적인 측면에서 FP32에 비해서 약 80배정도 메모리 사용량을 절감하는 효과를 가져왔다고 한다. 속도개선에 대해서는 채널수, Conv Layer의 크기에 따라서 실험을 진행했을때 약 58x 속도 향상이 있었다고 한다. BWN와 XNOR-Net과의 비교는 없어서 아쉬운 부분이 있다.
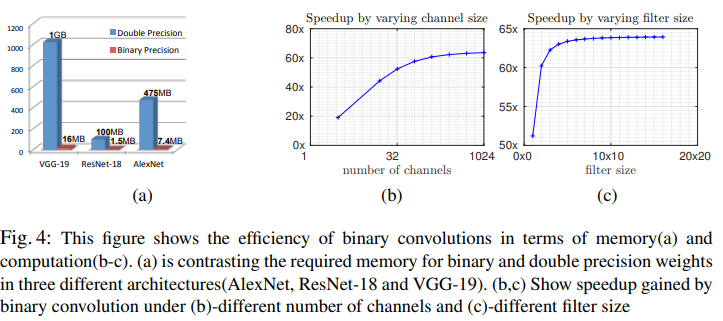
아래 그림의 파란색선을 살펴보면 XNOR-Net의 결과보다는 BWN의 결과가 더 좋은것을 알 수 있다. 해당 XNOR-Net은 FeatureMap에 대해서도 양자화를 진행하기 때문에 양자화 오류가 더 발생해서 생긴 정확도 손실임을 알 수 있다. 메모리 사용량이 얼마만큼 절감되는지는 체크를 해보아야겠으나, 개인적인 생각으로는 BWN 대비 XNOR-Net의 정확도 손실률이 너무 크다고 보여진다.


XNOR-Net에서 Block구조에 따라서도 실험을 진행하였을때, Conv Layer가 처음있던경우에는 Top-1 30.3%, 3번째로 옮긴경우 44.2%로 매우 큰 차이를 보였다. 양자화오류를 고려한 네트워크 설계가 중요하다는것을 보여주는 사례이다.
Conclusion
1-Bit 양자화는 양자화 오류가 상당하기 때문에 연구적인 성격으로만 남아있으며 실사용으로는 거의 사용되지 않는 추세이다. 실사용을 위한 양자화는 경량화 대비 정확도 손실이 가장적은 8-Bit 양자화가 대세를 이뤄나가고 있다. 하지만 1-Bit 양자화의 연구는 지속적으로 이어지고 있으며 XNOR-Net은 그 연구의 시작점에 있기에 꼭 알아두도록 하자.








최근댓글