지금까지 학습했던 양자화 내용을 실습해보고자 Pytorch를 활용해 적용을 하는 과정에서 발생했던 이슈사항에 대해서 공유를 해보고자 한다. 우선 접근했던 방법으로는 Github에서 가장 스타를 많이 받은 코드를 활용하여 ImageNet이나 CIFAR10과 같은 데이터셋으로 간단하게 테스트를 진행하였다.
Issue1. Bit Operation
앞서 살펴보았던 논문 XNOR-Net, DoReFa-Net, Bi-real Net 에서는 가중치와 활성화출력이 모두 이진화가 되어있기 때문에 Bit Operation을 이용하여 계산한다.
XnorNet: Dot product between two binary vectors can be implemented by XNOR-Bitcounting operations.
DoReFaNet: the dot product of x and y can be computed by bitwise operations as...
Bi-Real Net: Moreover, as the activation is also binary, then the convolution operation could be implemented by the bitwise XNOR operation and a bit-count operation.
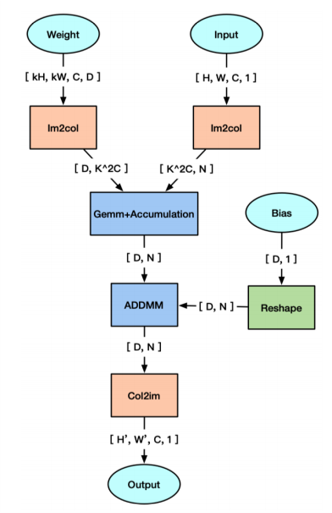
하지만 실제로 Pytorch에서는 Convolution operation을 연산할때 GEMM(General Matrix Multiply)방식으로 계산이 된다. GEMM 방식은 우리가 알고있는 단순 행렬연산이다. 그럼 Pytorch에서 Conv 연산이 어떻게 동작하는지 잠시 살펴보자.

Input 행렬에 대해서 Weight와 겹치는(Overlap)되는 영역의 윈도우에 대해서 열백터로 만들어준다. 그림에서 보면 첫번째로 겹치는 빨간색 행렬인 `[[3, 9], [2, 8]]`이 열벡터로 reshape되어 `[[3], [9], [2], [8]]`이 되어 Window1을 생성한다. 두번째로 겹치는 파란색 행렬인 `[[9, 0], [8, 1]]`이 열벡터로 reshape되어 Window1 오른쪽에 붙게된다. 이때 행렬의 형태는 `[[3, 9], [9, 0], [2, 8], [8, 1]]` 이 된다.
이러한 방법으로 Weight에 대응되는 Input 행렬을 모두 열벡터로 만들어 새로운 행렬을 구성한다. 그리고 Weight에 대해서 행백터 형태로 쭉 펼쳐준 후, 우리가 알고있는 곱하고 더하는 행렬연산을 수행한다. Bias에 대해서 더하기 연산을 추가하면 Convolution Operation이 수행이 된다.
A Computing Kernel for Network Binarization on PyTorch라는 논문에서는 Pytorch에서 Bit Operation을 구현하였으며 github에 공개하였다. 하지만 사용하기 까다롭기도 하며 무엇보다 Pytorch Official이 아니기 때문에 일반적 상황에서 성능보장이 어렵다는 문제가 있다. 위 3개의 논문도 모두 C++로 코드공개를 해두었으며, Pytorch에서는 이 문제를 해결할 방법이 없었다.
Issue2. Full-Precision to Low-Precision
Pytorch에서 제공되는 Tensor의 데이터 타입은 기본적으로 float32를 가진다. Int8 타입까지 지원을 하고 있으나 그 이하의 데이터타입은 지원하지 않는다. 1-Bit 데이터타입 표현하려면 Boolean 타입을 이용하면 가능하지만 이렇게 하는것은 일반적이지는 않은것 같다. DoReFa-Net의 Official github에서는 다음과 같이 표현하고 있다.
This code release is meant for research purpose. We're not planning to release our C++ runtime for bit-operations. In this implementation, quantized operations are all performed through tf.float32. They don't make your network faster.
즉, 모든 연산은 float32를 통해서 이루어지고 Bit-Operation도 제공할 계획이 없으므로 실제로는 네트워크가 경량화가 되거나 전혀 빨라지지 않는다고 설명한다.
Result
며칠동안 이 문제에 대해서 끙끙 앓고있다가 자료조사를 통해 알게 되었다. 결국 1-Bit의 Low Precision은 적용하기 어렵다는 사실이다. 추후에 QAT(Quantization-Aware Training)와 관련된 논문을 작성하려고해도 Python으로 구현에 있어 상당히 에로사항이 있을것 같다는 생각이 든다.
그래도 다행인것은 Pytorch에서 Quantization API를 제공하고 있으며 16-Bit Float, 8-Bit Int 자료형을 제공하고 있다. 양자화를 하는 방법은 또한 위 논문에서 제시한 방법과는 매우 다를것이므로 다음 포스팅에서는 Quantization API에 대해서 자세히 다루어 보도록 하겠다.








최근댓글